Serverless computing is the latest hot technology causing waves in public cloud environments. The hype suggests that it is disrupting software engineering and promises to eliminate operational complexity, meaning developers can fully focus on functionality and user experience. No longer having to provision infrastructure when the workload changes or not having to pay for idle time are clearly tempting, however, it would be prudent to retain some level of scepticism as not all that glitters is gold.
At Beyond Now, we’ve been using AWS serverless technology for quite some time which has yielded a wealth of benefits for our clients. I’ve been exploring the use of serverless technology in data migration from legacy systems to new IT environments, typically a notorious pain point when handling IT transformation projects. The data needs to be extracted through cumbersome interfaces from the old environment, then cleansed, transformed, and seamlessly loaded into the new environment while limiting the outage for customers, as well as back office staff.
Most likely the system you are migrating to is already cloud-native, possessing all the great benefits such as elasticity, scalability, and robustness. Maybe you are even migrating to a SaaS solution and the whole infrastructure including scalability and capacity management, performance tuning, infrastructure protection, monitoring and so on are no longer your concern as they’re handled by the SaaS solution provider. Therefore, beside data cleansing, you only need to make sure that the code for your migration scripts works and does not become the performance bottleneck in the whole process.
In many ways, the majority of work for most data migration projects is relatively similar to traditional system integration tasks and therefore, the purchase of new software is not necessarily required. It’s about automatically transforming the data correctly and calling the right APIs of the new system to load the data. However, there are a few differences when implementing a migration project compared to system integration:
Serverless technology is an ideal candidate to implement the necessary functions for transforming and loading the data in your migration process. You can implement the microservices for the transformation logic in the programming language of your choice using a serverless computing platform such as AWS Lambda. Orchestrating the transformation steps as well as API calls for the extract, transform and load process of the data using a serverless function orchestrator such as AWS Step Functions. A new test environment can be spun up in no time as the infrastructure transparently scales, allowing you to seamlessly process small amounts of data but also test the full data set without concern about provisioning new environments. You only pay for the infrastructure when the data is actually being processed; no costs are incurred while your code is idle and you are not performing migration test runs.
During our most recent BSS transformation project, we have implemented the data migration process using serverless technology from AWS. The entire process for transforming the data and loading it into the target system through APIs was implemented using AWS Lambda orchestrated by an AWS Step Function. The source data of the migration process was stored in an S3 bucket and AWS DynamoDB was used to maintain the status of the flow. The migration process was exposed through a REST API via the Amazon API Gateway so that it was easy to use and test.
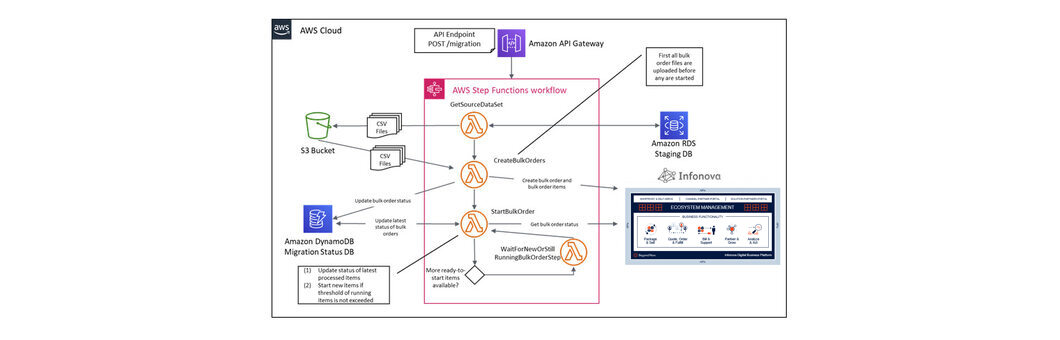
This architecture enabled us to perform the first migration test run with real data just two weeks after start of the development. From there, we iteratively refined the transformation functions and tested the migration until all data quality issues were resolved. Due to the serverless architecture, we didn’t have to provision infrastructure for spinning up or tearing down test environments but could perform test runs at any time which greatly sped up the data cleansing process.
We were able to process large data sets at any point in time without concern about costs for heavyweight testing infrastructure, nor the endless discussions about how many environments we could get. Throughout the entire development and testing process of the data migration, the monthly infrastructure costs remained below 10 USD per month. A single test run did not cost more than just a few cents. This was probably less than 10% of the infrastructure costs that we would have incurred with a traditional development and test infrastructure in the public cloud for a similar sized project.
Of course, there were not huge amounts of data to be migrated in this scenario, just slightly above 200,000 subscribers. But even for a migration of millions of customer records, we would not expect more than a couple of 100 USD per month for a virtually unlimited number of extremely high performing test environments. And the best part, we would not have to provision any infrastructure to scale the solution for a larger number of customers.
Serverless computing is still a relatively new concept, so ambiguity about its tangible benefits remains and there are clearly challenges to face moving forward. A skills gap when it comes to serverless programming is to be expected, however, in my opinion the biggest challenge continues to be the estimation of the costs when it comes to using serverless technology.
It's impossible to know metrics like the number of requests as well as processing duration and memory allocation in GB-seconds for a single Lambda function, or to guess the number of read and write requests for a serverless database like DynamoDB. In reality, you will most likely have to rely on the knowledge that serverless technology will be cheaper than the provisioned infrastructure if the workload is not constantly running and needs to scale up during peaks. In order to optimize the costs, your software architects will also need to consider the charging metrics of underlying services in their design.

